

SnapLogic eXtreme Aims To Drive Simplicity, Lower Costs To Build & Run Data Lakes, Cloud-Based Big Data Services 
Later this summer, SnapLogic will launch SnapLogic eXtreme, an extension to its drag-and-drop iPaaS technology to make it easier and less costly to build, populate and run data lakes for complex processing on popular cloud-based big data services. IDN speaks with SnapLogic’s Mark Gibbs.
by Vance McCarthy
Tags: Amazon, Azure, big data services, cloud, data lakes, EMR, integration, SnapLogic, Spark,

senior product manager
"We’re significantly decreasing the operational time, cost and skills needed to take advantage of cloud-based data lakes and services."

SnapLogic is building on its drag-and-drop pipeline approach to making SaaS integration easy and code-free to speed and simplify delivery of big data and analytics services.
Later in August, SnapLogic is set to launch SnapLogic eXtreme, an extension to its SnapLogic Enterprise Integration Cloud (EIC) platform to make it easier to design, build, populate and run data lakes for complex processing on popular cloud-based big data services.
SnapLogic eXtreme will work with Amazon Elastic MapReduce (EMR), Microsoft Azure HDInsight, and Google Cloud Dataproc.
“Just as we democratized data and app integration for IT and citizen integrators, we are extending our [cloud-based] capabilities to bring the same time and cost benefits to integrating big data services,” said James Markarian, CTO of SnapLogic.
Under the covers, SnapLogic eXtreme leverages many of the data and connector services from the company’s EIC platform to let users easily build Apache Spark pipelines (and supporting data lakes). Notably this all happens without the need to write complex code, Mark Gibbs, SnapLogic senior product manager told IDN.
In addition, SnapLogic eXtreme will automate a lot of the gnarly issues often required to manage such environments, he added.
“We’re significantly decreasing the operational time, costs and skills needed to take advantage of cloud-based data lakes and services,” Gibbs said.
“We’re looking to become more data-driven, and help companies more easily collect and analyze data from all the different data sources -- whether that's from traditional on-premise sources, such as relational databases like Oracle or Teradata, or cloud-based data resources,” he said.
Gibbs further described why SnapLogic’s experience as a provider of an enterprise-class iPaaS for integrating SaaS data makes a great precursor for growing data-centric use cases.
“All SaaS-based applications have mounting amounts of data that need to get analyzed, as well as web logs and streaming IoT data sources. We intend to make them all more easily available for analysis,” he said.
In fact, Gibbs shared with IDN that many core design features of SnapLogic eXtreme arise directly from conversations with customers looking for easier and less costly ways to “more easily capture diverse data sources and be able to land them in a repository that makes sense,” Gibbs added. That led engineers to work on ease-of-use for non-technical users, as well as automation and lifecycle management capabilities for IT.
Exploring How SnapLogic eXtreme Drives Self-Service for Data Analysts
When SnapLogic talks about ease-of-use, it’s not simply a conversation about pretty GUIs, Gibbs emphasized. “It’s overall about helping business users get to the data they need faster,” he added.
“Think of SnapLogic eXtreme as just a new execution environment for us,” Gibbs told IDN. “It enables line of business users to be able to create complex [Apache] Spark pipelines and execute on the data integrations they need – without coding or IT. This is not just simple, but it brings speed to the [multiple] iterations, these users often want to do.” As a result, Gibbs said, “we can really help business ‘close the loop’ on these iterations much faster, so they can get to the results they’re looking for much faster.”
In this context, IDN asked Gibbs to describe the type of learning curve for non-technical users.
“If you're familiar with SnapLogic and you know how to build pipelines now, you're essentially trained in SnapLogic extreme. So it's the same UI. It’s a different SnapPack that is specific to enable the building in the Spark pipelines. The way you put them together and the way that you manifest itself is exactly the same,” Gibbs said.
For non-technical users, SnapLogic eXtreme offers a front-end GUI and rapid iteration. “One of the big advantages that we bring is ease of use. If you look at what a lot of companies are doing, a lot of data engineers are writing code -- or they're using a tool that generates code. We're looking to enable [less technical] line of business users through our UI to rapidly build their own data pipelines without the need for coding. . . People need to still have some technical knowledge of the ecosystem, but they don't need to have intimate knowledge of Scala or Python code to be able to get any insights out of Hadoop.”
How SnapLogic Helps IT Modernize & Automate Data Analytics Infrastructure
Beyond features for the end user, SnapLogic eXtreme also sports features to help enterprise IT modernize their traditional data infrastructure.
For data engineers, SnapLogic eXtreme lets them land data in storage services like Amazon S3 or Azure Data Lake Store with “just a few clicks,” Gibbs said. “This is due largely to SnapLogic’s expanded library of 450 pre-built connectors,” he added. The engineers can then quickly create Apache Spark pipelines with SnapLogic’s “ephemeral plex capabilities” to more easily process large volumes of data from various endpoints using popular managed big data services from Amazon, Microsoft or Google. “This results in a substantially lowered barrier to creating cloud big data architectures for data engineers while empowering companies with massive cloud compute power and cost efficiencies,” he added.
SnapLogic also has features for top line officials charged with set up and management of the whole big data infrastructure, or what SnapLogic calls the “org admin.” SnapLogic eXtreme makes it easy for these admins to get the project rolling.
In specific, SnapLogic’s eXtreme provides pre-integrations, UI and management services.
“We will go ahead and spin up an EMR cluster,” Gibbs said. “For example, all you do is you do a one-time definition and give us some parameters around how many initial nodes you want to start with. And then just tell us whether you want to auto scale or not. From that point forward, SnapLogic takes care of maintaining and a whole lifecycle management of that cluster.”
As an example, if an org admin submits a pipeline and bring up five nodes, but then a cluster runs out of resource because of other workloads, SnapLogic can autoscale that cluster to accommodate the larger workload. “And then, when the workload is complete and it’s idle for a certain amount of time, we will also actually tear that cluster down. We’ve heard from customers that’s very very valuable.”
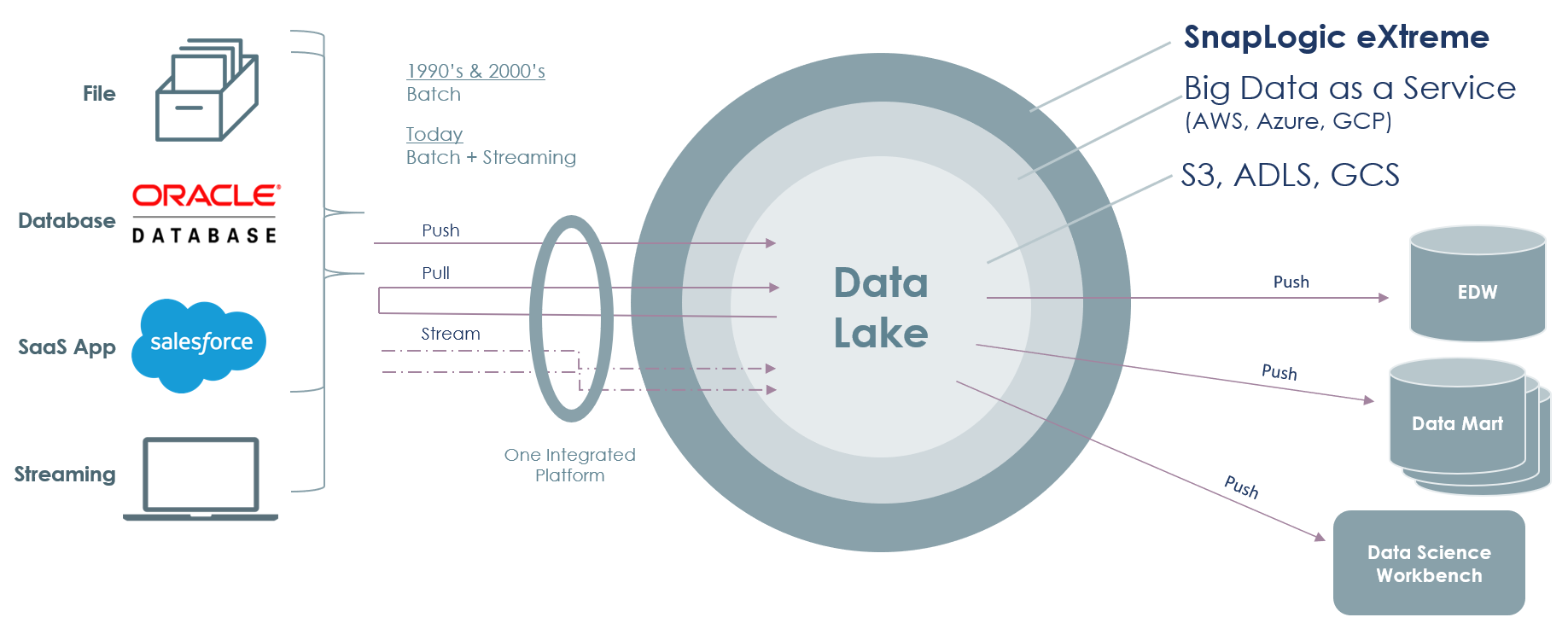
The Choice (and Challenge) of Migrating To Cloud -- Data Lakes, Big Data as a Service
As data volumes and variety explode, more and more companies are looking to transition to the cloud, but aren’t always happy with the options they’re offered, Gibbs noted.
“The overwhelming choice for working with multiple types of data are data lakes versus a data warehouse,” Gibbs said. A big reason for data lakes’ popularity, he added are because they can store all kinds of data – relational, structured, semi-structured or unstructured data. Add to that flexibility, a cloud-based approach to data lakes, users get extensibility and flexibility along with lower costs for capex and staff, he said.
Gibbs described how SnapLogic eXtreme looks to deliver all these benefits as companies move from data warehouses to the cloud or even modern big data as a service options from Amazon, Microsoft and Google.
Phase One may start with simple steps to expand the capacity of a traditional data warehouse, but that can often hit a wall or run into operational inefficiencies.
Phase Two comes into play as two things happen: Data types and volumes expand, and the time allowed to access such data gets shorter. “One of the ways they're progressing here is they're saying to us, ‘Okay, I need to move off of on-prem,’” Gibbs said. “To do so, customers typically take their on-premise cluster and move it to the cloud, to take advantage of an IaaS (infrastructure as a service),” Gibbs added.
While there are benefits in Phase Two, Gibbs also pointed out that customers will “end up with a bunch of nodes in their VPC. And, then they will again go through the installation process of their distribution in the cloud. Customers are still stuck managing their cluster.”
Enter Phase Three, or what Gibbs calls a ‘third evolution’ of thinking about data for analysis. In this third stage, customers are starting to adopt cloud managed big data services. So they’re looking at Amazon EMR, Microsoft HDInsights, Google Cloud Dataproc among them.
This ‘phase three” is the sweet spot for SnapLogic eXtreme., Gibbs said. “We’re finding, when you go into a more of a cloud managed service [for data], the whole environment can be managed on your behalf. So it's a much cleaner environment and a much easier environment to work in. That is probably the main learning that we've had,” he said.
Survey Shows IT is ‘Falling Behind’ on Data Analysis Projects
SnapLogic eXtreme is being release just as a new study reveals that enterprise IT is falling behind when it comes to launching data analysis projects that can quickly deliver business value.
SnapLogic surveyed some 500 enterprise IT decision-makers found “despite the clear business case for data investments, enterprises struggle to reap the rewards, held back by manual work, outdated technology, and lack of trust in data quality.”
In an effort to help enterprise decision-makers crystalize their thinking (and strategic plans) around such a widespread issue, the report offered some key take-aways:
Big on vision; Lagging on execution: Nearly all (a whopping 98%) of respondents said they are in the process of (or planning for) digital transformation. But, only 4% consider themselves are ahead of schedule.
Enterprises are drowning in data; Not always using it effectively: Nearly three-quarters (74%) say they face “unprecedented volumes of data,” but admit they are still struggling to generate useful insights from it. Respondents estimated that their organization uses only about half (51%) of the data they collect or generate. For all the floods of data, less than half (48%) of all business decisions are based on data.
Plan to invest in data analysis projects is up: As ROI from data seems more quantifiable: The average business plans to allocate more than $1.7 million to preparing, analyzing, and operationalizing data in five years’ time – more than double the nearly $800,000 they are spending today. Respondents estimate an annual revenue increase of $5.2 million as a result of more effective data use, organizations stand to benefit from a potential 547% return on their initial investment.
Customer data tops the list as the most valuable: 69% of surveyed respondents said customer data is among the most valuable in their organization, followed by IT (50%) and internal financial (40%) data.
Manual data work wastes time and resources: IT respondents report they spend 20% of their time simply working on data and preparing data for use. This includes low-level tasks (manual integration for datasets, applications, and systems; building custom APIs; etc.
Legacy technology impedes data efficacy: A vast majority (80%) report that “outdated technology” holds their organization back from taking advantage of new data-driven opportunities.
Trust and quality issues slow progress: Only 29% of respondents have complete trust in the quality of their organizations’ data. This lack of trust in data is blamed on: inconsistencies in data formats, inadequate tools, challenges with interdepartmental sharing, and the sheer volume of data.
Hopeful view of AI for tackling data challenges: 83% of respondents see potential in AI to help tackle their data challenges. In fact, more than one-quarter (27%) say they are already investing in AI and machine learning technologies. A further 56% plan to invest in this area. The majority of respondents say AI and machine learning will help their organization to automate data analysis (82%), data preparation (73%), software development (66%), and application integration (63%).
Simplicity, Flexibility & Automation Will Drive New Levels of Data Lake Success, SnapLogic Says
By providing features enterprise IT, data engineers and LOB, Gibbs said SnapLogic eXtreme aims to support multiple options for how a company decides to implement a data lake architecture.
“You can just take everything in and throw it in a data lake, and that’s often handled from a central IT perspective. Or, companies may want more specific business use cases, a ‘customer 360 view’ for example. That’s where line of business would have a specific [implementation] requirement,” Gibbs said. SnapLogic eXtreme can handle both scenarios and can even provide what Gibbs called ‘data ponds’ for truly tailored and specific business needs.”
SnapLogic eXtreme will be available as GA at the end of August.
Related:
- SolarWinds Brings “Resilience’ to IT Ops for Agentic AI and Autonomous Operations
- Tray Enterprise-Class AI Platform Casts Light on “Shadow MCP” and Controls “AI Sprawl”
- Xano 2.0 Updates Production Grade Backend for AI, Apps To Solve "Vibe Coding Trap"
- Ai4 2025 Vegas Wrap-Up: What Enterprises Need to Know About Emerging AI Solutions
- Boomi Agentstudio Looks To Deliver Full-Featured Management Platform for AI Agents
All rights reserved © 2025 Enterprise Integration News, Inc.