

MapR Adds Deep Kubernetes Integration To Ease Support for AI/ML & Dynamic Apps, Workloads 
MapR Technologies is making it easier to build and run AI/ML, analytics and other dynamic workload projects. The MapR Data Platform’s native Kubernetes integration can scale compute and storage resources independently. IDN talks with MapR’s Suzy Visvanathan.

senior director for
product management
"Organizations are realizing the relationship between compute and storage is no longer a 1:1 relationship. So, we’re letting customers scale [them] independently."
MapR Technologies is making it easier to build and run projects with dynamic workloads, such as AI/ML and analytics projects. MapR’s latest data platform supports native Kubernetes integration to let users scale compute and storage resources independently.
“The nature of workloads is shifting, so we set out to provide customers a more flexible approach,” Suzy Visvanathan, MapR’s senior director for product management told IDN.
“Customers traditionally have co-located compute and storage But organizations are starting to realize the relationship between compute and storage is no longer a 1:1 relationship. Some apps will require more CPU and others may need more storage. You shouldn’t have to buy more of one than the other if you don’t need to. So, we’re letting customers scale [them] independently.”
This is truly the case with the new crop of AI/ML and analytics apps, she said.
“Today's AI/ML and analytics workloads can be bursty and unpredictable,” she said. As a result, provisioning infrastructure for maximum load compute scenarios can prove costly, and worse, it can increase complexity and administrative overhead. “In many new use cases, compute tends to have peaks while storage needs do not. Kubernetes solves for some of this by letting organizations orchestrate and spin up containers as compute needs arise,” she said.
And while bringing Kubernetes to bear for these types of dynamic workloads may seem like a no-brainer, challenges can persist. “Using Kubernetes however is not automated and it can be a quite complicated process,” Visvanathan said.
Enter MapR’s latest update, which eliminates much of the handcrafting and abstracts gnarly complexity.
MapR Power To Deploy Native Apache Spark, Drill Apps in Kubernetes
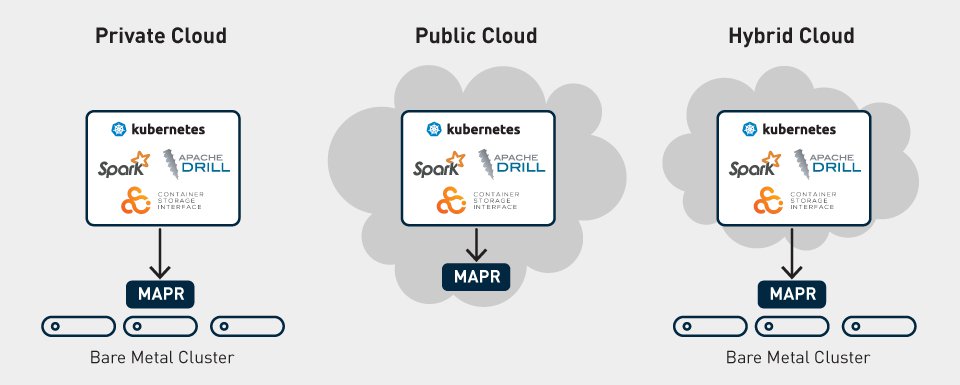
Architecturally, the latest MapR Data Platform can deploy and run Apache Spark and Apache Drill as compute containers orchestrated by Kubernetes - without Hadoop. MapR’s deployment model allows end users including data engineers to run compute workloads in a Kubernetes cluster that is independent of where the data is stored or managed.
MapR also made the management of Kubernetes clusters easier, she added, thanks to its work to abstract much of the granular complexity and use of simple-to-use APIs.
Further, the MapR-XD file system is available as a persistent volume. This simplifies the process of spinning up compute to be available when and where customers need it, Visvanathan added.
MapR’s senior vice president for engineering Suresh Ollala shared how MapR’s engineering makes tasks easier. “[MapR’s] deep integration with Kubernetes core components, like operators and namespaces, allows us to define multiple tenants with resource isolation and limits, all running on the same MapR platform. This is a significant enabler for not only applications that need the flexibility and elasticity but also for apps that need to move back and forth from the cloud.”
In fact, thanks to MapR’s updates, users gain benefits across their app or analytics lifecycle, with the ability to:
- Better handle compute needs that are bursty and unpredictable;
- Run compute jobs (such as Apache Spark and Apache Drill queries) in a true multi-tenant environment. This ensures tenants do not starve each other of precious resources such as CPU and memory;
- More easily deploy and scale compute- even across different and multiple environments, including on-premises, public, and hybrid cloud; and
- Effectively manage novel use cases (e.g., next-gen apps and data lake) in an increasingly hybrid cloud environment.
Feature-wise, the MapR release includes these core capabilities:
Tenant Operator: This creates tenant namespaces (Kubernetes Namespaces) for running compute applications, allowing for a simple way to start complex applications in containers within Kubernetes. An end user can run Spark, Drill, Hive Metastore, Tenant CLI, and Spark History Server in these namespaces. These tenants can, in turn, point to a storage cluster that is located elsewhere.
Spark Job Operator: This creates Spark jobs, allowing for separate versions of Spark to be deployed in separate pods, facilitating the multiple stages of dev, test, and QA that are typical in a data engineer’s workflow.
Drill Operator: This starts a set of Drillbits (Drill daemons), allowing for auto-scaling of queries based on demand.
CSI Driver Operator: This is a standard plugin to mount persistent volumes to run stateful applications in Kubernetes. [This plugin is based on the Container Storage Interface via the Cloud Native Computing Foundation (CNCF). MapR announced support for CSI earlier this year.]
How Explosion in Apache Spark Adoption is Shifting the ‘Dynamic’ Imperative
There is one other important dynamic that pushed MapR to deepen its support for Kubernetes, Visvanathan told IDN: The huge explosion in Apache Spark adoption.
“Spark jobs are winning,” Visvanathan told IDN. “A lot of organizations may start with 100 Spark jobs. But very quickly, they have 1,000 or 2,000 jobs.”
Once customers have Spark jobs – and the data they need, she said the ability to run Spark on containers and use Kubernetes is the next step to improvement, Further, Spark workloads can make direct use of Kubernetes clusters for multi-tenancy, sharing and administrative tasks.
MapR’s most current release is just the latest stage in MapR’s Kubernetes support. In early 2019, MapR enabled persistent storage for compute running in Kubernetes-managed containers through a CSI compliant volume driver plugin.
One analyst sees a lot of merit in MapR’s latest updates for AI/ML and analytics projects.
“Having run a recent survey on organizations’ use of containers to support AI and analytics initiatives, it is clear that a majority of them are exploring the use of containers and Kubernetes in production,” said Mike Leone, senior analyst at Enterprise Strategy Group. “We are also seeing compute needs are growing rapidly and bursty due to the unpredictability of compute-centric applications and workloads. MapR is solving for this need to independently scale compute while also tightly integrating with Kubernetes in anticipation of organizations’ rapid container adoption.”